¡¡BOMBAZO!! La secuencia genética que la OMS da para identificar el virus está presente en el gen 8 de todos los humanos
La web PieceOfMindful publicó una noticia rompedora: «Una de las secuencias de cebadores de la OMS en la prueba de PCR para el SARS-CoV-2 se encuentra en todo el ADN humano.»
La secuencia «CTCCCTTTGTTGTGTTGT» es una secuencia de cebador de 18 caracteres que se encuentra en el documento de protocolo de prueba de PCR de coronavirus de la OMS. Las secuencias del cebador son las que se amplifican mediante el proceso de PCR para ser detectadas y designadas como resultado de prueba «positivo». Da la casualidad de que esta misma secuencia exacta de 18 caracteres, literalmente, también se encuentra en el cromosoma 8 del Homo sapiens. Por lo que puedo decir, esto significa que los kits de prueba de la OMS deberían dar un resultado positivo en todos los seres humanos. ¿Alguien puede explicar esto de otra manera?
Realmente no puedo exagerar la importancia de este hallazgo. Como mínimo, debería tener un impacto notable en los resultados de las pruebas.
¡Guau! Que crack el tío. Ha descubierto él solo que esto del coronavirus es una pantomima que se han montado todos los gobiernos del mundo, en connivencia con todos los científicos y todos los sanitarios del planeta. Y lo ha hecho él solo, con su ordenador.
La noticia se ha ido replicando como la pólvora y hoy me ha llegado a mi. A ver si consigo explicarlo fácil, para que hasta el autor de ese blog pueda entenderlo. Pocas semanas después de que se detectase el virus, se logró secuenciar su código genético. Una vez secuenciado, se puede utilizar una prueba PCR para diagnosticar si el virus está presente en una muestra obtenida del paciente.
Como ya expliqué en otra entrada anterior, el virus Sars-Cov-2 es un virus RNA, es decir, que tiene una única hebra de nucleótidos. Lo primero que hay que hacer es transcribir una copia inversa para obtener una cadena doble, algo que es necesario en las pruebas PCR, que están pensadas para detectar secuencias de ADN (de doble cadena). Esto se consigue añadiendo a la muestra una enzima llamada transcriptasa inversa.
Si en la muestra está el virus, ya se habrá duplicado creando una doble hélice de nucleótidos.
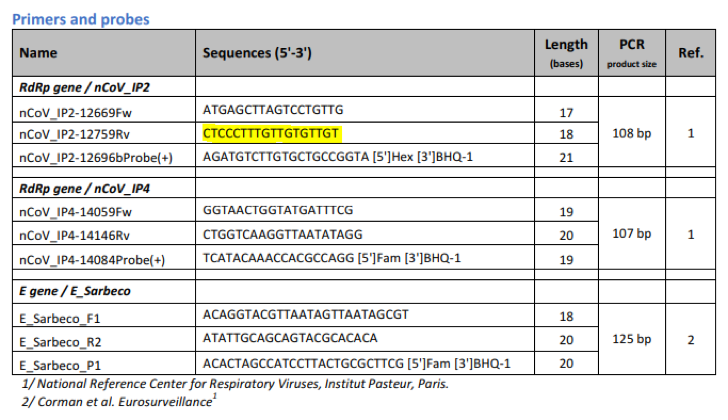
Ahora podemos hacer la PCR. Para ello necesitamos utilizar dos cebadores o iniciadores. Uno llamado directo y el otro inverso. En la tabla de la OMS del inicio del artículo podemos verlo. para identificar el gen IP2, tenemos el iniciador directo ATGAGCTTAGTCCTGTTG, y el inverso CTCCCTTTGTTGTGTTGT.
¿Cómo funciona esto?
No sé si os acordaréis de los nucleotidos o si nunca los habéis estudiado. Hay varios: la Adenina, la Guanina, Timina, Citosina… Si nunca has oído hablar de ello puede que te suenen a frutas tropicales que no has probado en tu vida, pero son realmente las moléculas que forman el ADN y que llevan toda la información genética que hace que tú seas tú y no otro.
Pero para no liarnos con los nucleótidos, vamos a usar números. Imaginad que queremos identificar la cadena de ARN 1-2-3-4-5-6-7-8-9 (en amarillo) que forma parte de la secuencia genética del virus, y que la identifico como bandera de que estamos contagiados. Utilizando la transcriptasa inversa, obtenemos la cadena complementaria.
![]()
Después sometemos la muestra a una temperatura de 90ºC para que se separen las dos hebras. Ese proceso se llama desnaturalización, y se realiza en un aparato que se llama termociclador en el que se programa la temperatura a la que hay que poner la muestra y el tiempo que tiene que mantenerse así.
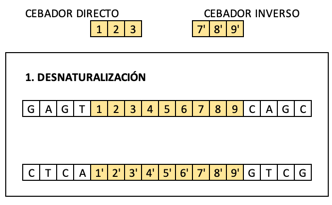
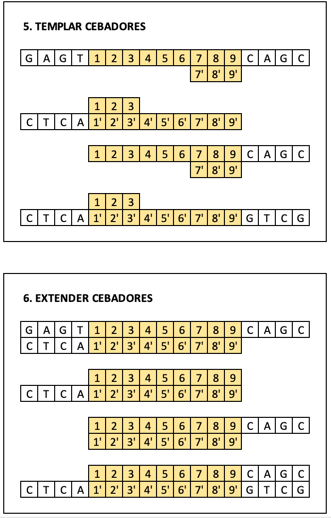
Para identificar la secuencia genética que buscamos, nos hemos creado una gran cantidad de cebadores (directos e inversos) que coinciden con el inicio y el fin del código buscado.
Estos cebadores se añaden a la muestra, junto con gran cantidad de nucleóticos y polimerasa, una enzima que provoca que se secuencien las nuevas copias.
Una vez que las hebras se han separado, los cebadores se colocan sobre ellas por afinidad química.
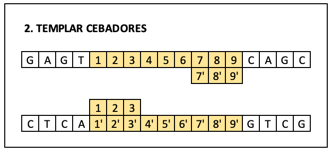
La polimerasa empieza a añadir nucleótidos solo en la dirección del cebador. Obteniendo unas copias incompletas de las hebras originales.
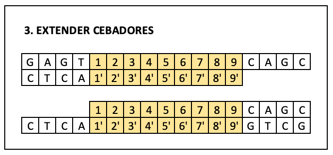
Una vez hecho esto, se repite el proceso de desnaturalización.
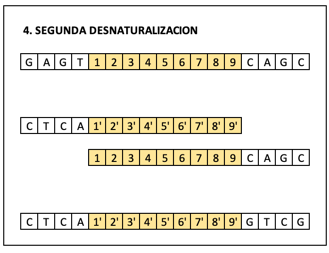
Y el proceso con los cebadores.
Obteniendo así multitud de réplicas del código buscado. El ciclo se repite 30 veces. Si tenéis nociones de informática eso es 230 copias del gen. Muchos miles de millones de copias. Si el gen está presente luego se puede detectar por fluorescencia. Si no lo está, no se habrá copiado y no aparecerá fluorescente.
Ahora bien, el autor del artículo de PieceOfMindful está confundiendo un cebador (123) con la secuencia buscada (123456789). Si el cebador directo está presente en el gen 8 del ser humano, se copiará una vez en cada ciclo, pero no se replicará exponencialmente porque el código asociado al inverso no está presente. La posibilidad de que haya un positivo por un error el los cebadores elegidos, es 0.




ffg
28/08/20 08:50
Gran trabajo jefe, más claro agua.
ffg
28/08/20 08:58
Pero claro, mientras se publiquen cosas como las presentes en «D salud.com» no es extraño que se sigan viendo tonterías como la que da lugar a este artículo. Eso sí, amparadas por la libertad de expresión
ffg
28/08/20 10:36
P. Ej.
https://www.youtube.com/watch?v=3x1_BxKJ_IU
lamentira
28/08/20 10:49
https://www.youtube.com/watch?v=FrYhGyolrCI
lamentira
28/08/20 20:35
No me digas eso Mesca. Que lo he explicado fácil
ffg
29/08/20 09:58
@ Mescalero:
Como siempre digo, a buen entendedor…
Afortunadamente el jefe se extiende lo suficiente como para que un entendedor malo, como es mi caso, y tirando de los vagos recuerdos de mis clases de biología y fisiología, pueda captar lo esencial de la explicación.
fdgfdgdfg
31/08/20 16:06
El coronavirus es una gran mentira para controlar a la poblacion, no hay duda de eso. Los tests son una verdadera farsa, no hay ningun contagiado, basta ya de creer en ese virus estupido
Jim
2/09/20 00:57
fdgfdgdfg Si crees que es una mentira, se solicitan voluntarios:
JAMC
6/09/20 10:01
Buen artículo. Como dices, simplemente si el primer complementario no está presente en la muestra (cosa que no se da en el DNA humano), no hay amplificación. Decir, además, que durante la RT de las RT-qPCRs que se hacen para detectar el RNA del virus (no es una simple PCR), las muestras se tratan previamente con DNasas que eliminan el DNA presente para que no interfiera posteriormente en la reacción.
Este primer (junto con su pareja) se utiliza además como control positivo añadiendo (en reacciones a parte), un RNA sintético.
Por último, decir que esos primers no se usan universalmente. Esos primers se utilizan en concreto en este protocolo:
https://www.who.int/docs/default-source/coronaviruse/real-time-rt-pcr-assays-for-the-detection-of-sars-cov-2-institut-pasteur-paris.pdf?sfvrsn=3662fcb6_2
Que es de los primeros que salieron. Posteriormente se han publicado otros protocolos y hay muchos que utilizan otras secuencias de oligos más largas y en otras posiciones del genoma del virus.
P.D: Para concluir. Es «enzima». «Encima» es un adverbio.
lamentira
7/09/20 18:32
@ JAMC:
Valiosa información. Gracias. Y corregido lo de encima
JAMC
13/09/20 09:56
@ lamentira:
No es molestia. Al contrario, gracias a ti por hacer esta labor de divulgación tan importante.